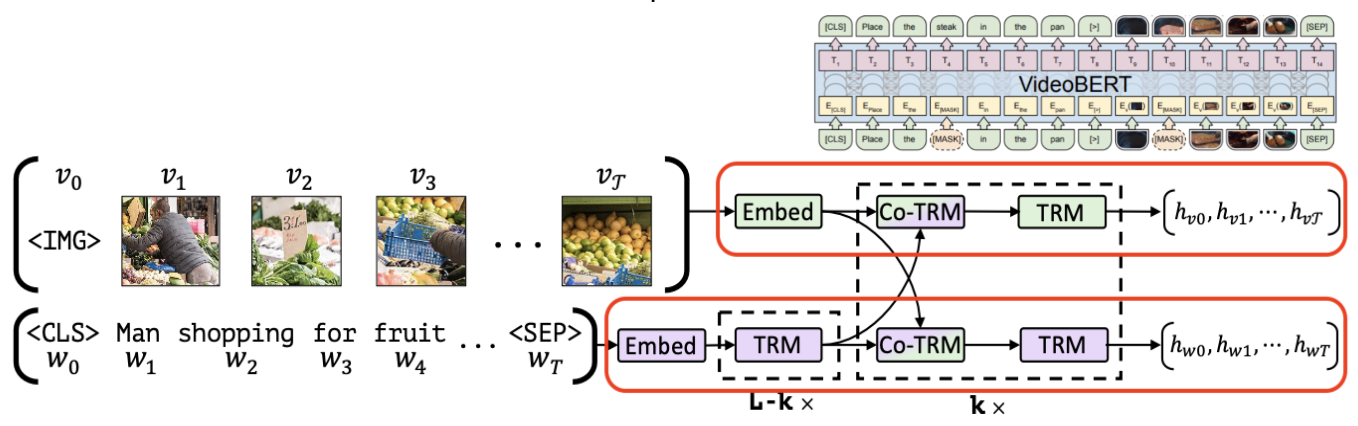
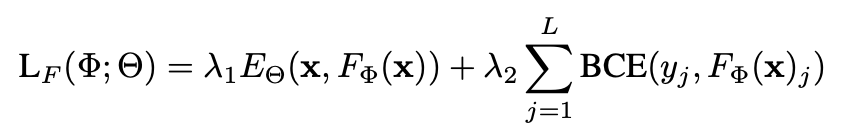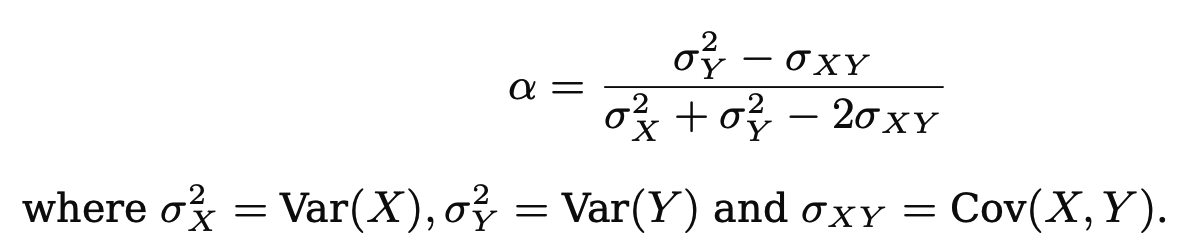저번에 공부한 SPEN의 한계점을 보완한 뉴립스 2022 paper SEAL에 대해 공부해 보겠다.BackgroundSPEN의 추론 과정은 test-time optimization을 하는데, 추론할 때도 backprop연산을 하며 각 \(y\)를 update 하였다.이런 식으로 추론하는 것을 Gradient based inference라 하며 이 방법은 상당히 느리고 불안정하다. 그래서 SEAL은 task-net과 loss-net으로 나눠 task-net에서는 GBI 없이 정답에 가까운 \(y\)를 바로 출력한다.대신 loss는 energy network를 통해 구조적 의존성을 반영한다.Introduction\(y\)들의 dependency를 모델링하기 위해 많은 방법이 있었다.implicit 하게 de..