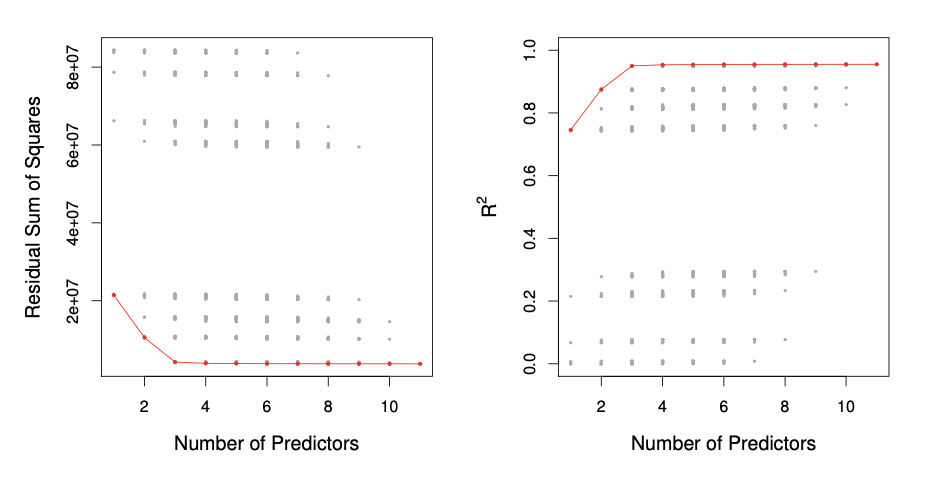
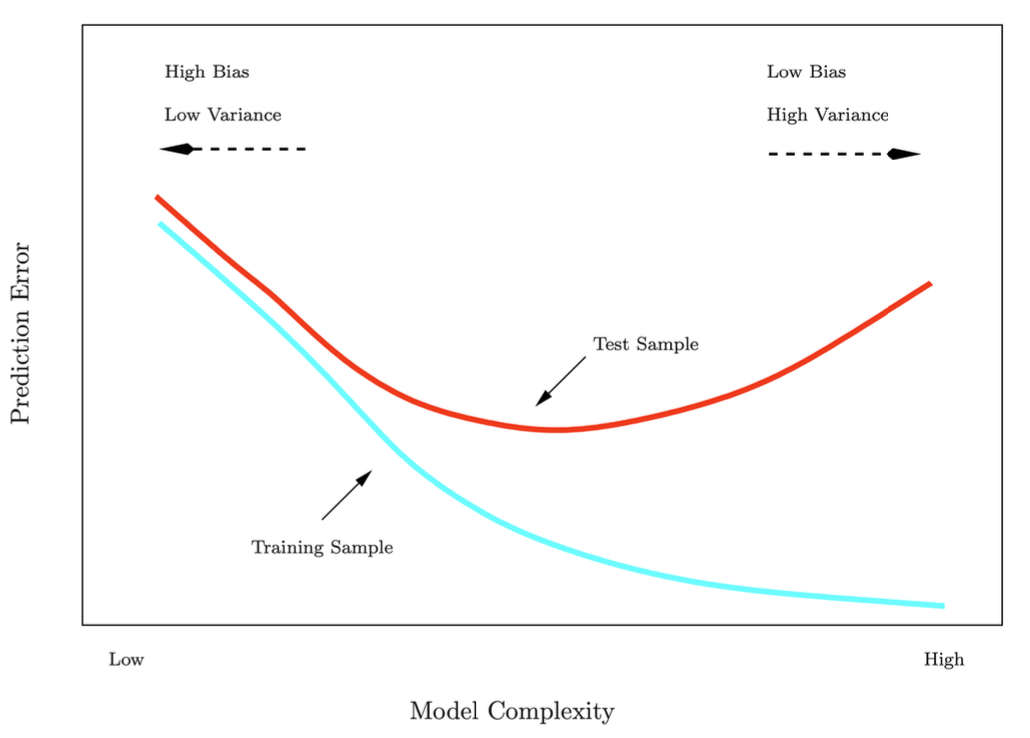
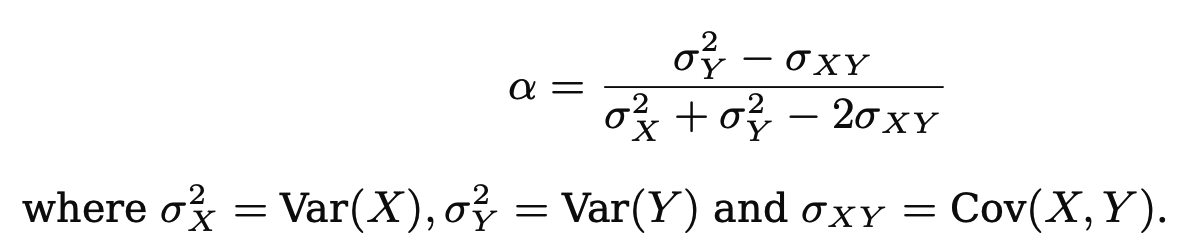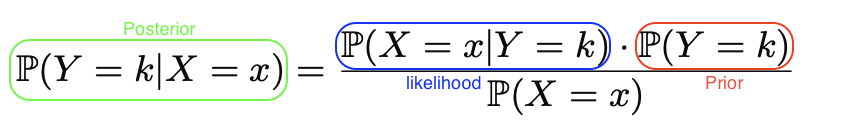오늘 공부할 내용은 저번에 공부한 Decision Tree의 성능을 향상하기 위한 방법이다.https://ysk1m.tistory.com/45 [Machine learning] Tree based Methods: Decision Tree로 Regression과 Classification하기Tree-based Methods분류와 회귀 작업 모두에 사용 가능하며, 입력공간을 재귀적으로 분할하여 단순한 영역으로 나눈다.이 방법은 시각적으로 이해가 쉽고, 해석력 높은 모델을 만들 수 있다. 단, 정ysk1m.tistory.com사실 오늘 정리한 내용은 Decision-Tree뿐만 아니라 machine learning의 성능을 향상하기 위한 general 한 method이다. 실제로 연구할 때는(paper를 쓸 ..