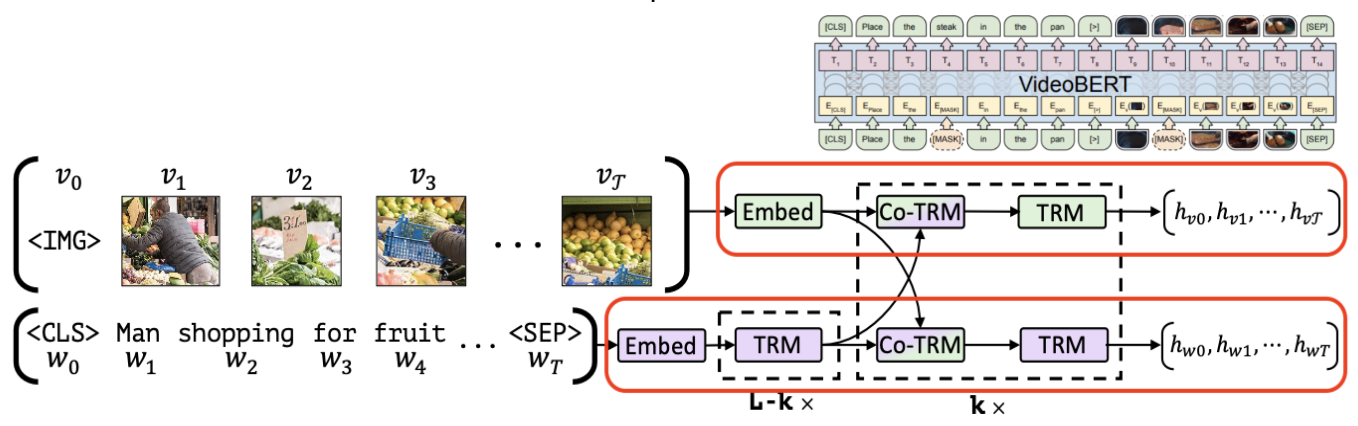
Motivation기존에는 Vision modal과 language modal을 같이 한 번에 학습하는 single stream 구조가 많았습니다.이 경우 각 modal뿐 아니라 두 modal에 대한 관계도 잘 학습하기 어려웠고 visual grounding이 필요한 task에 대해서 성능이 좋지 않았습니다. 그래서 이 paper에서는 각각의 modal를 잘 학습하고 두 modal의 관계 또한 잘 학습하여 visual grounding이 필요한 task를 잘하는 모델을 만드는 것이 목표입니다. 또한 이러한 visual grounding이 pretrain이 가능하고 transfer learning도 가능하다는 점을 보여줍니다.Approach첫 번째로 보면 visual stream과 language stre..