저번 글은 Tranformer의 원리에 대해 간단하게 알아봤다면 이번 글은 학습이 어떻게 이뤄지고 어떻게 응용될 수 있는지에 대해 자세하게 공부해 보겠습니다.
Self-Attention 또는 Attention에 대해 잘 모르신다면 제 전 글을 읽어보시고 이 글을 읽는 것을 추천드려요!!ㅎㅎ
[Deep learning] Transformer에 대한 기본 아이디어
요즘 Transformer에 대해 공부하고 있어 여러 강의와 책을 듣고 기록해 놓은 내용입니다. 기본 아이디어부터 실제로 어떻게 학습하는지 수식적으로 이해해 보는 시간을 가지겠습니다. 저는 'Easy!
ysk1m.tistory.com
[Deep learning] Attention Mechanism에 대하여
Attention Mechanism에 대해 알아보도록 하겠습니다. Attention Mechanism은 Context Vector를 어떻게 표현하고 그렇게 했을 때 개선된 점이 어떤 것인가?라는 의문을 가지고 접근하면 쉽게 이해할 수 있습니다
ysk1m.tistory.com
이번 글도 이준석 교수님의 강의 내용을 토대로 정리한 내용이니 참고해 주세요.
먼저 인공지능을 이용하여 우리가 주로 하던 task는 무엇이 있었죠?
네 아마 대부분 Classification 또는 Regression문제를 풀었던 것을 기억하실 겁니다.
그럼 트랜스포머를 이용해서 Classification task을 어떻게 할까요?
트랜스포머는 Sequence-level prediction과 Token-level prediction을 할 수 있습니다.
이때, Token Aggregation이라는 개념이 나옵니다.
Token Aggregation
입력 벡터 가장 앞단에 dummy token([CLS]=분류를 위한 토큰)을 붙여줍니다.
이 토큰(벡터) 또한 Self-Attention을 통해 값이 나오고 그 값이 전체 Sentence을 분류하는 기준이 됩니다.
Token-level prediction을 할 경우, 각 입력 벡터의 transform 값을 기준으로 분류 작업을 합니다.
그림으로 자세하게 살펴보면 다음과 같습니다.

[CLS] 토큰으로부터 만들어진 Z_0은 X_1,.., X_4 중 어느 한 벡터에도 편향되지 않았기 때문에 Sentence 전체에 대한 Classification의 기준으로 사용할 수 있습니다.
어떤 식으로 Task를 하는지 알았으므로 이제 Transformer 모델 구조를 하나하나 살펴보며 공부하도록 하겠습니다.

먼저 Encoder부분의 Multi-Head Attention에 대해 알아보도록 하겠습니다.
Multi-Head Attention(in Encoder)
Multi_Head Attention은 쉽게 여러 개로 self attention을 하고 합치는 것이라고 생각하면 됩니다.

예시 문장을 들어 Multi-Head Attention이 왜 유용한지 알아보겠습니다.
David gave a cloth to Ehtan because he liked cloth라는 문장이 있을 때 he가 가리키는 것이 John일까요 David일까요?
이렇게 대명사가 있을 경우 문맥을 파악해서 판단해야 합니다.
여러 개로 self attention을 하는 경우 어떨 때는 he를 John으로 생각하고 어떨 때는 David로 생각합니다.
단일 Attention은 하나의 관계만 학습할 수 있지만 Multi-Head Attention은 다양한 해석을 고려할 수 있습니다.

이때 multi head의 개수에 따라 W_0차원도 고려해줘야 하는데요. 그 이유는 Transformer는 같은 길이의 sequence가 들어가 같은 길이의 sequence가 나와야 되기 때문이죠.
Attention is all you need paper에서는 self-attention을 8번 했습니다. 그래서 그만큼 W_0의 row 차원개수를 늘려 Z가 다시 동일차원으로 임베딩 될 수 있도록 해줍니다.
다음은 Encoder의 Multi-Head Attention 다음에 있는 Feed Forward의 역할에 대해 알아보겠습니다.
Feed Forward
이 Feed Forward 층은 그냥 표현을 조금 바꿔주는 역할로 생각하시면 됩니다.
가중치를 곱하고 bias를 더하여 좀 더 표현을 변형시켜 주는 것으로 이해하면 됩니다.
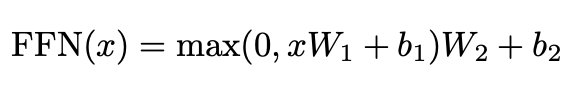
Feed Forward 층이 깊어지다 보면 학습의 안정성에도 문제가 생기고 기울기 소실 문제가 발생할 수 있습니다.
이러한 문제를 해결하기 위한 개념인 Residual connection과 layer normalization에 대해 간단히 설명드리도록 하겠습니다.
Residual connection & layer normalization
Residual Connection은 모델의 입력과 출력을 더하는 방식으로 입력 정보를 유지하고 기울기 소실 문제를 방지하는 역할을 합니다.

layer normalization은 각 layer의 출력값을 정규화하는 방식입니다.
입력 데이터의 평균과 분산을 조정하여 학습을 더 안정적이고, 빠르게 할 수 있습니다.
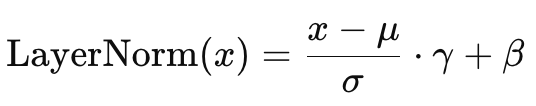
이렇게 쭉 보다 보면 문장은 단어들 마다 순서가 있는데 이건 어떻게 학습하는지 궁금하실 겁니다.
RNN을 이용한 모델의 경우 순차적으로 학습하기 때문에 별다른 처리 없이 학습을 진행했으면 되었는데요.
트랜스포머는 RNN의 구조를 탈피한 것 이기 때문에 새로운 방법이 필요합니다.
트랜스포머에서 위치정보를 표현하기 위한 방법인 Positional Encoding에 대해 설명드리도록 하겠습니다.
Positional Encoding

삼각함수의 주기성을 이용하는 것이 특징입니다.
\(pos\)는 입력 토큰의 위치(몇 번째 토큰인지), \(d_{model}\)은 임베딩의 차원을 나타냅니다.
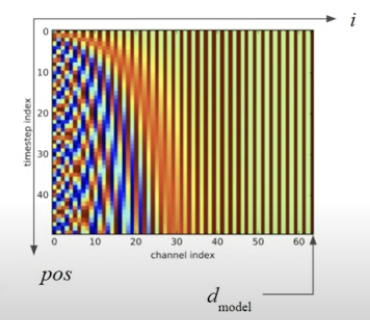
그래프를 보면 즉, i가 작을수록 주기성이 짧아지기 때문에 \(pos\)(단어 순서)에 따라 급격하기 바뀌는 것을 알 수 있습니다.
i가 클수록 주기성이 길어지기 때문에 \(pos\)에 따라 완만하게 바뀝니다.
이러한 특성을 통해 임베딩 앞쪽 차원은 단어들의 local 한 관계를 학습하며, 뒤쪽 차원은 단어들의 global 한 관계를 파악한다고 할 수 있습니다.
여기까지가 Encoder가 input을 받아서 transform 하여 벡터로 만드는 내용에 대한 설명입니다.
Encoder와 비슷한 부분이 많아 차이점 위주로 알아보도록 하겠습니다.
Masked Multi-Head Attention
트랜스포머에서 가장 중요하고 기본적인 내용 중 하나가 트랜스포머는 항상 입력과 같은 크기의 토큰을 출력한다는 것이었죠.
Decoder에서도 트랜스포머의 이런 특성 때문에 Mask token이라는 개념을 도입합니다.
t시점에서 decoding을 하기 위해서는 1부터 t시점까지는 입력을 해주고 나머지 시점은 mask token으로 채워줍니다.
layer를 지나 next token을 예측해 주고 다음 decoding 할 때 사용해 주면 됩니다.
Multi-Head Attention(in Decoder)
빨간 박스(Multi-Head Attention in Decoder)를 보면 파란 박스(Multi-Head Attention in Encoder)와 입력이 다른 것을 알 수 있습니다.
Query는 바로 밑 layer에서 올라오고 Key와 Value는 Encoder로부터 오고 있습니다.
이 작업은 번역 작업이기 때문에 past 단어들로만 next 단어들을 예측하는 것이 아니라 문장 전체의 의미도 같이 고려해 주기 위해서입니다.

이후 Feed forward layer와 softmax를 통해 예측값 나오게 합니다.
이러한 모델의 구조를 봤을 때, RNN구조에 비해 크게 3가지 정도 장점이 있습니다.
먼저 이전출력에 영향을 받지 않으므로 병렬적으로 처리하는 것이 가능해졌습니다.
그리고 Interpretability가 높습니다.
multi-head를 이용하여 각각 학습한 내용을 이용할 수 있기 때문입니다.
마지막으로 Long-Range Dependency 학습에 유리합니다.
모든 단어가 각각 직접 연결되므로 아무리 멀리 떨어져있더라도 두 단어의 관계를 충분히 학습할 수 있는 장점이 있습니다.
'Machine learning & Deep learning' 카테고리의 다른 글
| [Deep learning] Metric learning 개념 정리 (0) | 2025.02.26 |
|---|---|
| [Deep learning] BERT 개념과 Minimalist Version of BERT 구현해보기 (0) | 2025.02.20 |
| [Deep learning] Transformer에 대한 기본 아이디어 (0) | 2025.02.17 |
| [Deep learning] Attention Mechanism에 대하여 (0) | 2025.02.16 |
| [Deep learning] LSTM과 GRU를 Vector combination 관점에서 살펴보기 (0) | 2025.02.16 |