Attention Mechanism에 대해 알아보도록 하겠습니다.
Attention Mechanism은 Context Vector를 어떻게 표현하고 그렇게 했을 때 개선된 점이 어떤 것인가?라는 의문을 가지고 접근하면 쉽게 이해할 수 있습니다.
기존 Seq2Seq 모델 구조는 인코더에서 하나의 동일한 Context Vector를 제공했고, 이는 정보가 뭉개지는(=마지막 토큰의 정보만 과도하게 담은) 문제를 불러왔습니다.
예를 들어, '나는' '인공지능을' '공부하는' '학생' '입니다.'라는 입력 토큰이 있을 때 Context Vector는 '입니다.'의 정보를 가장 크게 담고 나머지 토큰은 뭉개집니다. 이럴 경우 모델의 성능의 한계가 있을 수밖에 없습니다.
이러한 한계점을 Attention Mechanism으로 극복하는데 수식과 함께 자세히 살펴보겠습니다.
Attention Mechanism
이해를 쉽게 하기 위해 번역의 예시를 들어서 설명해 보도록 하겠습니다.
'나는' '인공지능을' '공부하는' '학생' '입니다.'라는 우리말을 영어로 번역하는 과정을 예시로 들겠습니다.

Encoder에 다음과 같이 입력 token이 들어올 때, 입력 token을 '어떻게' 조합하여 Context Vector를 만들지 고민해야 합니다.
그러기 위해서는 Decoder부분을 동시에 살펴봐야 합니다.
Decoder의 초기 상태는 다음과 같습니다. 첫 번째 입력으로 시작을 알리는 <start> 토큰과 Encoder의 마지막 hidden state를 받습니다. 그럼 이제 Decoder에서는 hidden state, Context Vector, 입력을 함께 고려하여 예측값을 출력해야 합니다.

여기서 Attention mechanism을 이해하기 위한 가장 중요한 개념을 설명드리도록 하겠습니다.
그것은 Query, Key, Value로 Attention Value를 구하기 위해 weighted sum을 하는 함수라고 생각하시면 됩니다.
Query : Decoder의 t시점의 hidden state
key : Encoder의 모든 시점에서의 hidden state
Value : Encoder의 모든 시점에서의 hidden state
Attention function : Attention(Q, K, V)= Attention Value
Query와 Key를 통해 Attention score를 구하고 Value에 대해 weighted sum을 하여 Context Vector를 만들어줍니다.
Attention score은 Q, K벡터를 각각 dot product를 하여 similarity를 구하고 그 similarity의 softmax을 적용하면 구할 수 있습니다.

Decoder의 첫 시점 hidden state은 Encoder의 마지막 hidden state로 대체합니다.
대체한 이 hidden state을 Query로 설정하여 Encoder의 모든 hidden state와 attention score를 구해 Context Vector로 표현합니다.
이렇게 구한 Context Vector와 Query로 사용한 Encoder의 마지막 hidden state를 concatenate 하여 입력값과 함께 계산하여 타깃값을 예측합니다.
여기서 중요한 점은 Decoder의 hidden state(Qeury)의 차원과 Encoder의 hidden state(Key)의 차원은 동일해야 하며, 다음 연산을 위해 concatenate 처리된 hidden state들은 이후 차원을 축소해야 합니다.
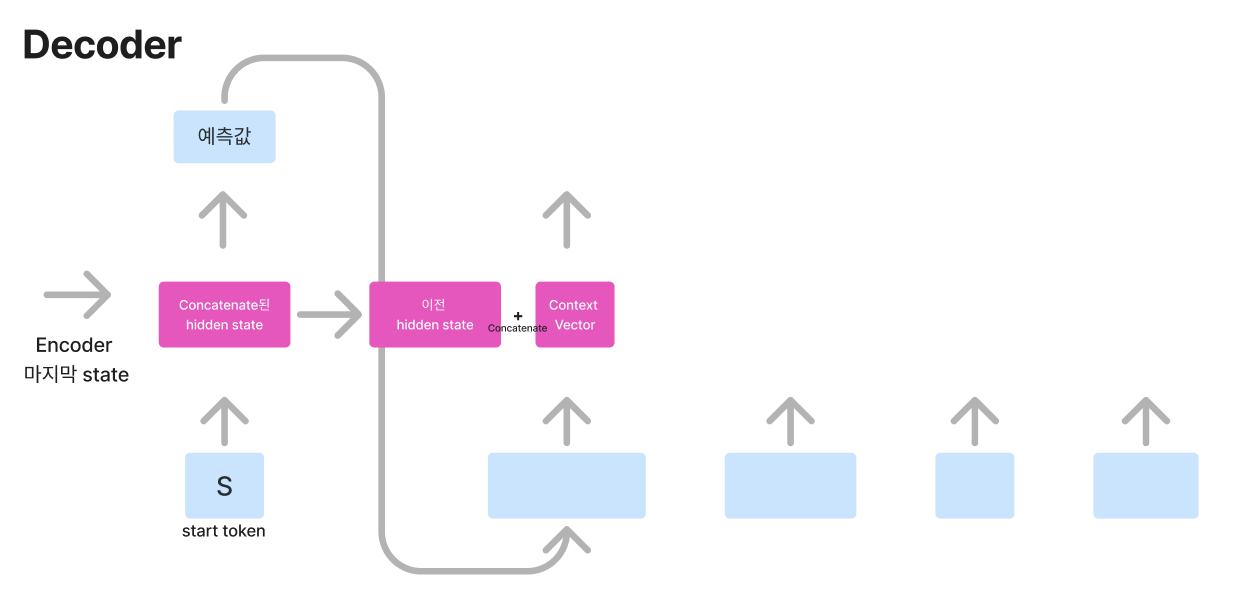
첫 번째 시점의 예측값을 두 번째 시점의 입력으로 사용합니다. 이때도 전 시점과 동일하게 이전 hidden state를 Query로 하여 Attention score을 구하여 Context Vector를 형성합니다.
Attention mechanism은 Encoder-Decoder 구조의 Seq2Seq 모델의 한계를 극복했지만 RNN이라는 구조에서부터 오는 근본적인 한계는 극복하지 못했습니다.
이후 Self-Attention을 이용한 Transformer 모델이 등장했고 RNN이라는 구조에서 부터 오는 근본적인 한계를 극복할 수 있게 되었습니다.
Self-Attention의 기본적인 아이디어에 대해 궁금하신 분들은 참고하세요!
[Deep learning] Transformer에 대한 기본 아이디어
요즘 Transformer에 대해 공부하고 있어 여러 강의와 책을 듣고 기록해 놓은 내용입니다. 기본 아이디어부터 실제로 어떻게 학습하는지 수식적으로 이해해 보는 시간을 가지겠습니다. 저는 'Easy!
ysk1m.tistory.com
'Machine learning & Deep learning' 카테고리의 다른 글
| [Deep learning] Transformer 자세히 공부한 것.. (0) | 2025.02.18 |
|---|---|
| [Deep learning] Transformer에 대한 기본 아이디어 (0) | 2025.02.17 |
| [Deep learning] LSTM과 GRU를 Vector combination 관점에서 살펴보기 (0) | 2025.02.16 |
| [Machine learning] Dropout 내가 궁금했던 모든 것 정리 (0) | 2025.02.15 |
| [Machine learning] Ridge Regression (0) | 2025.02.15 |