저번에 공부한 SPEN의 한계점을 보완한 뉴립스 2022 paper SEAL에 대해 공부해 보겠다.
Background
SPEN의 추론 과정은 test-time optimization을 하는데, 추론할 때도 backprop연산을 하며 각 \(y\)를 update 하였다.
이런 식으로 추론하는 것을 Gradient based inference라 하며 이 방법은 상당히 느리고 불안정하다.
그래서 SEAL은 task-net과 loss-net으로 나눠 task-net에서는 GBI 없이 정답에 가까운 \(y\)를 바로 출력한다.
대신 loss는 energy network를 통해 구조적 의존성을 반영한다.
Introduction
\(y\)들의 dependency를 모델링하기 위해 많은 방법이 있었다.
implicit 하게 dependency를 capture 하는 것으로 방법으로는 Feedforward 구조가 있다.
특정한 구조 관계를 정해주지 않고 학습시키는 것인데 implicit하게 구조가 학습되는 것이다.
이 방법은 빠르고 쉽지만 dependency를 포착할 수 있는 측면에서 한계가 있다.
explicit 하게 dependency를 표현하고 학습할 수 있다.
대표적인 예시로 SPEN이 있다.
하지만 이 방법은 학습이 불안정하고 느린 단점이 있다.
SEAL은 이 두 방법의 장점만을 이용한 것인데..
Structured Energy Network as Loss
설명의 편의를 위해 feedforward network는 task-net이라 하고 structured energy network는 loss-net이라 하겠다.
SEAL framework는 두 개의 parametric componets로 구성돼 있다.
loss-net \(E_{\theta}\)은 loss \(L_E\)에 의해 train 되고 task-net \(F_{\phi}\)는 loss \(L_F\)에 의해 학습된다.
train이 끝나고 난 뒤에는 loss-net은 더 이상 사용되지 않는다.
inference time에는 단지 task-net만 이용된다.
task-net을 학습하기 위한 loss function은 다음과 같다.
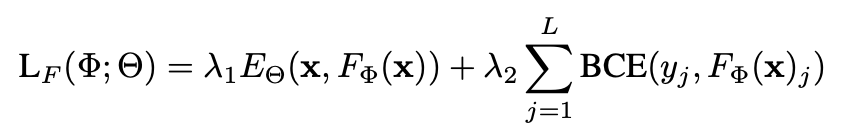
첫 번째 항은 feedforward \(F_{\phi}(x)\)의 출력을 energy net에 넣어 라벨 간의 관계에 대해 학습한다.
두 번째 항은 multi-label classification에서 자주 쓰이는 loss로 학습 초기 안정성에 기여한다.
둘을 합쳐 구조도 잘 배우고 안정적으로 수렴할 수 있도록 한 것이다.
energy net \(E_\theta\)에 대해 더 자세하게 알아보면 local term과 global term으로 이뤄져 있다.

\(E_{\theta}^{local}(x, y)\) term은 \(x\)와 각 \(y_i\)들의 관계를 모델링한다.
local term은 \(y_i\)가 1일 때만 더해지고 \(b_i^\top T_E(\mathbf {x})\)을 통해 얼마나 유사한지를 확인한다.
더 유사한 값이 많을 수록 loss로 전달되는 값이 커서 줄이려할텐데 이 이유는 energy score가 낮을 수록 서로 더 관계가 있는 것이기 때문이다.
다시 정리하면 pair가 더 높은 관계가 있으니깐 loss로 보내 값을 줄여 energy score 측면에서는 값을 낮추려하는 것이다.
\(E_{\theta}^{global}(x, y)\)는 \(y\)들의 관계를 파악하여 label간 상호작용을 요약한 값을 출력한다.
SEAL-static
task-net loss \(L_F\)는 loss-net의 성능에 의존한다.
따라서 loss-net parameters \(\theta\)를 잘 찾는 것이 중요하다.
이러한 loss-net을 먼저 학습하고 고정된 loss-net으로 task-net을 학습하는 것이다.
먼저 \(\theta\)에 대한 추정치 \(\hat{\Theta}\)을

여러 loss function을 이용하여 pretrain시킨다.
고정된 loss-net을 기반으로 task-net \(F_{\phi}(x)\)을 학습 시킨다.

SEAL-dynamic
이렇게 학습한 추정한(pretrain한) \(\hat{\Theta}\)은 energy space를 정확하게 표현하지 못할 수 있다.
따라서, task-net의 pair \((x,F_{/phi}(x))\)에 초점을 맞춰 loss-net을 dynamically estimate하는 방법이다.

Energy losses \(L_E\)
- Margin-based: SPEN에서 사용했던 SSVM loss이다.

SPEN은 가장 헷갈리는 \(\tilde{y}\)를 찾는 것도 optimize(GBI)를 했다.
그러나 infNet paper에서 Task-net과 loss-net을 동시에 adversarial하게 학습했는데 이는 SEAL-dynamic+margin loss의 특별한 경우라 본다.
- Regression-based: 정답과의 유사도를 측정하여 energy를 예측하자는 것이다.
\(\tilde{y}\)와 정답 \(y\)사이의 similarity score를 구하고 \(x\)와 \(y\) pair의 에너지를 sigmoid 함수를 통해 확률적으로 보자는 것이다.
0과 1간의 차이를 줄이기 위해 binary cross-entropy를 이용한다.

- Noise-contrastive ranking: ground truth의 에너지는 낮추고 noise있는 sample들은 에너지를 높여 ranking을 하여 맞추는 학습 방식이다.

noisy candiate \(\tilde{y}\)을 task-net의 output 분포에서 sampling하고 ground truth \(y\)와 비교한다.
이럴 경우 분포 전체에 대해 학습할 수 있어서 single point를 학습하는 것보다 성능이 좋다.