본 글은 이준석 교수님의 강의를 듣고 정리한 내용입니다.
Multimodality
원래 통계학에서 나오는 단어로 예를 들어 분포가 있을 때 분포 하나하나 mode가 있는데 여러 분포가 있으면 multimodal이라고 합니다.
인공지능에서는 음성, 이미지, 비디오, 텍스트와 같은 다양한 형태의 데이터들이 multimodal이라고 할 수 있습니다.
Examples of visual-text multimodal tasks
- Text-based image/video retrieval(search)
- Image/video Captioning
- Visual Question and Answering
- Spatial localization
- Temporal localization
Image Captioning
NCE
Nce는 기본적으로 positive pairs와 negative pairs를 구분하는 binary classification문제입니다.
Captioning task에서는 이미지와 caption의 positive pair \( ((I_1,c_1),...,(I_M,c_M)) \)로 구성하고 이미지와 caption의 negative pair \(((I_1,c_{not1}),...,(I_N,c_{notN}))\)로 구성합니다.
negative pair의 \(c_{not1}\)은 M개의 positive pairs 중 \(c_1\)이 아닌 무작위 값입니다.
all class에 대해 score를 계산할 필요 없이 fake examples을 sampling 하여 real examples의 score는 최대화하고 fake examples의 score는 최소화합니다.
Show, Attend, and Tell
이미지를 Show 하고 공간적 정보를 attention연산을 하여 단어를 출력하는 모델입니다.
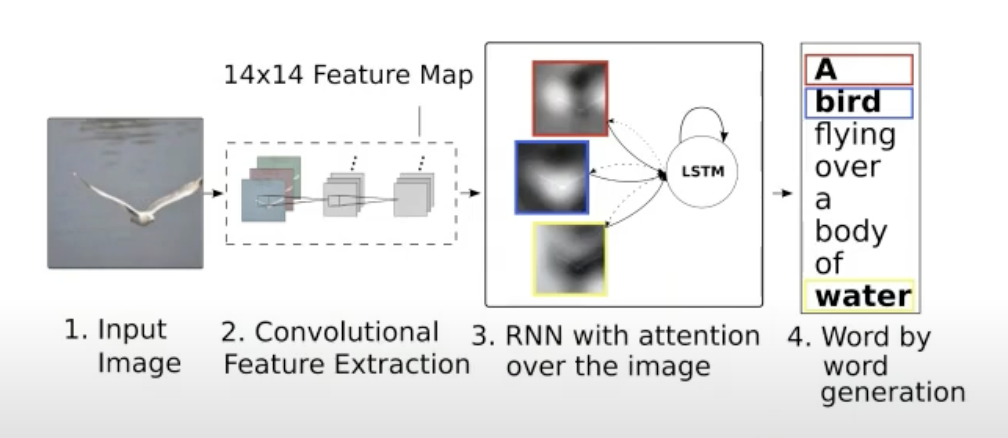
기존 attention 연산은 문장에서 어순대로 했다면(temporal) 이 모델에서는 spatial 한 정보를 attention 합니다.
입력된 이미지를 CNN을 통과시켜 feature map을 만들어줍니다.
이것을 pooling 하여 Query로 이용하고 Pooling 전 feature map을 Key, Value로 이용합니다.
Video Captioning
Image의 Show, attend, and tell모델과 비슷한 내용입니다.
단, 여기서는 비디오 프레임 단위로 학습하기 때문에 temporal attention을 이용합니다.
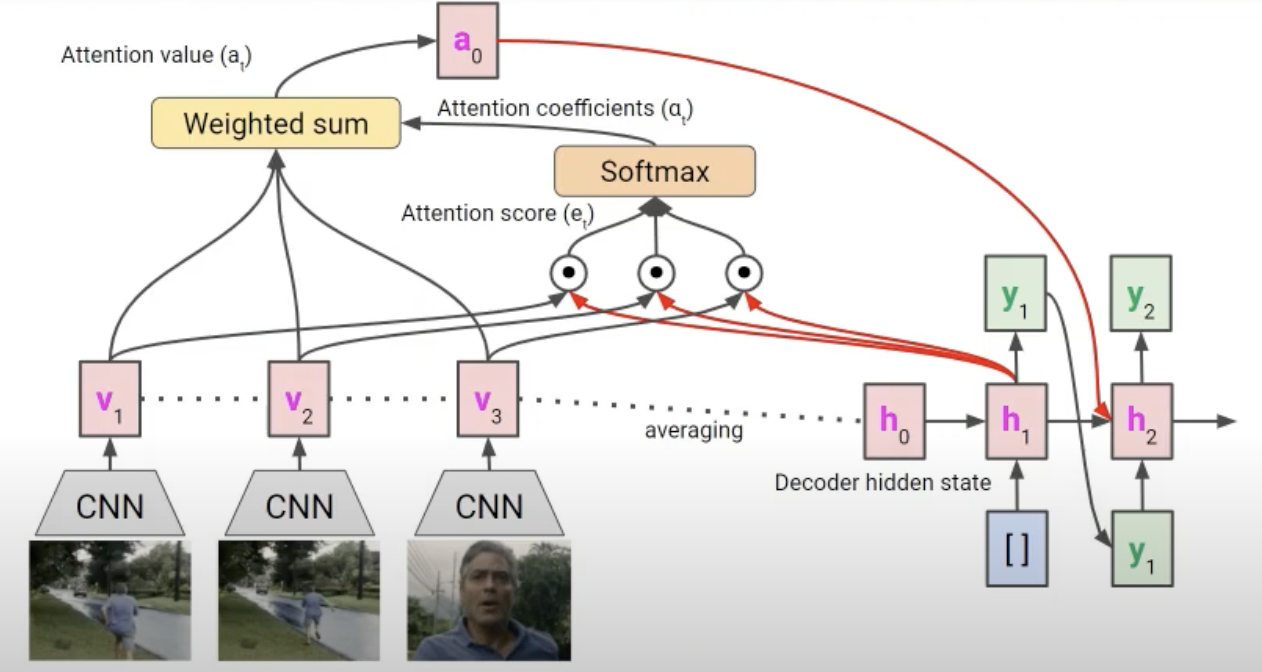
Transformer based Image-Text model
VL-BERT
Training example: 한 장의 이미지와 그것의 caption으로 구성되어 있습니다.
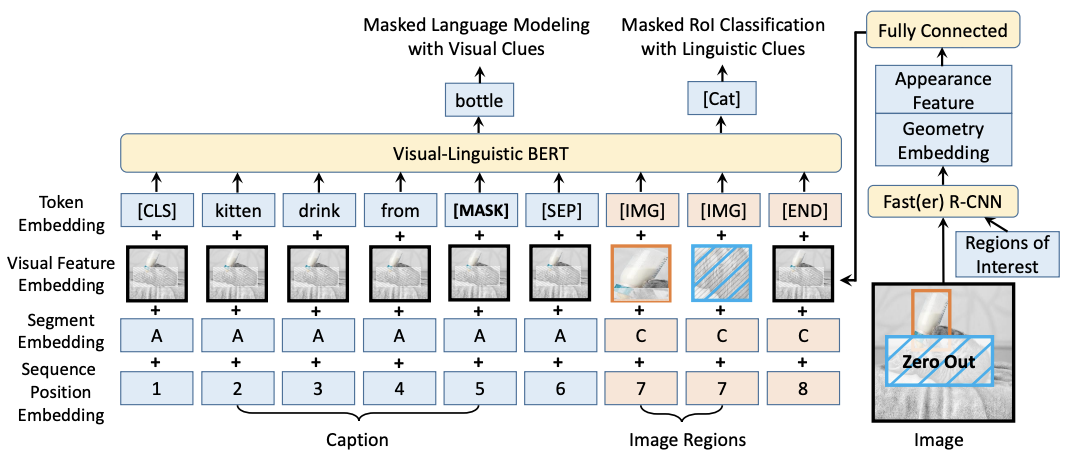
[SEP] 토큰을 기준으로 앞은 Caption embedding이 들어가고 뒤는 이미지가 들어갑니다.
BERT에서는 3가지 임베딩을 합쳐 입력으로 들어가는데 VL-BERT는 Visual Feature Embedding이 추가로 들어갑니다.
caption 토큰 쪽에는 이미지 전체에 대한 데이터(검은색 box)를 전달해 주고 뒤쪽은 image objection을 하여 검출된 모든 부분을 입력으로 사용합니다.
특히 image regions에서 image의 특정 부분을 Mask 하여 Zero Out으로 만듭니다. 이 부분을 classification 하는 문제로 전환하여 학습을 진행합니다.
여기서 Segment Embedding의 경우 A, B, C 3가지 토큰이 있는데 VQA task에서 text가 2개가 들어가 Q: A, A:B로 임베딩 할 수 있습니다.
Masked Language Modeling with visual clue + Masked ROI classification with linguistic Clues을 통해 multimodal을 어떻게 학습하는지 알 수 있습니다.
VQA task에 대해서도 다음과 같이 학습됨을 알 수 있습니다.

VilBERT
VL-BERT와 비슷한 개념인데 조금 다릅니다.
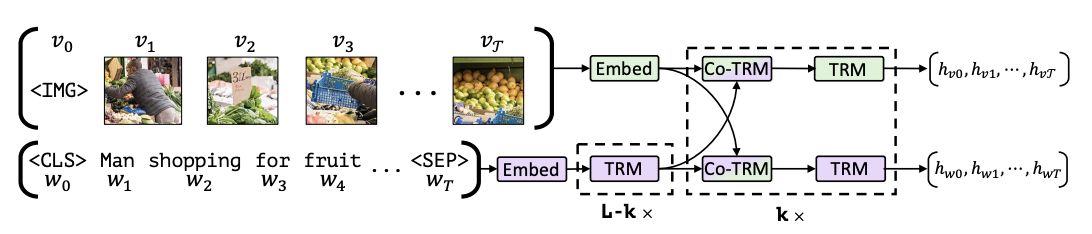
VilBERT는 image 쪽 transformer와 text 쪽 transformer로 구성합니다.
여기서 특징적인 것은 Regular transformer block과 Co-attention Transformer layer로 구성됩니다.
특히 Co-attention Transformer는 image transformer 부분은 Query(image), Key(text), Value(text)로 구성하고 text transformer 부분은 Query(text), Key(image), Value(image)로 구성합니다.
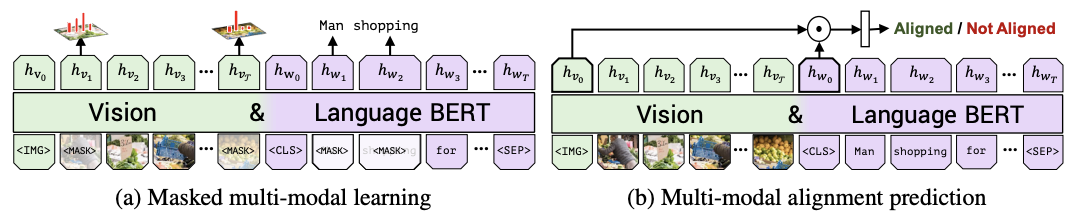
이 모델도 BERT의 학습방법과 동일하게 MLM task와 NSP task를 수행합니다.
'Machine learning & Deep learning' 카테고리의 다른 글
| [Machine learning] ML 1주차 공부(Linear Regression 모든 것) (0) | 2025.03.09 |
|---|---|
| [Deep learning] Multi-Modal learning Part2 (0) | 2025.02.28 |
| [Machine learning]Energy-based Models(part1) (0) | 2025.02.27 |
| [Deep learning] Metric learning 개념 정리 (0) | 2025.02.26 |
| [Deep learning] BERT 개념과 Minimalist Version of BERT 구현해보기 (0) | 2025.02.20 |