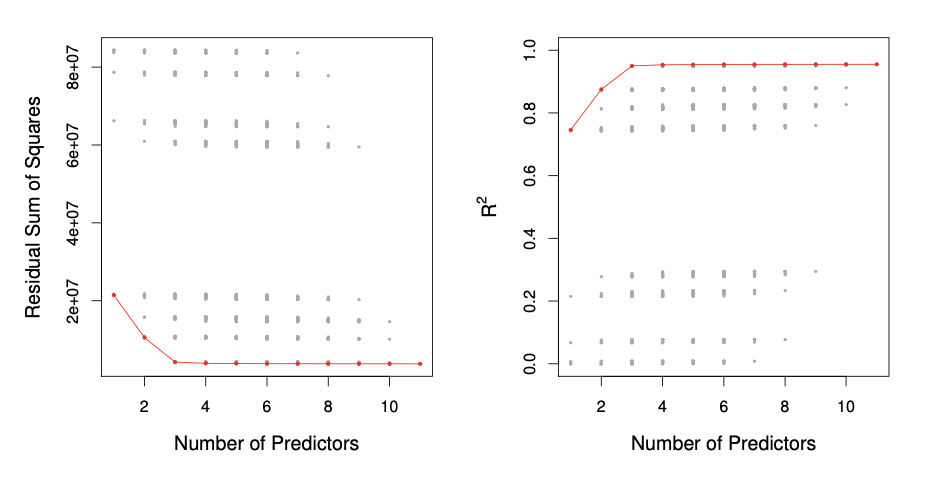
모델의 feature의 개수가 증가하면 Accuracy가 높아진다.그러나 모델이 복잡해지므로 interpretability가 낮아지고 coefficient의 분산이 커지므로 새로운 값에 대해 예측이 불안정하다. 이런 점 때문에 단순히 feature의 개수만 늘려서 모델의 성능이 좋아진다고 판단하면 안된다. feature를 어떻게 고를 것이며 몇개를 골라야할지에 대해 공부해보도록 하겠다. Best Subset Selection모든 조합을 전부 살펴보는 것이다.1단계: Null Model(\(\mathcal{M}_0\)) 설정아무 predictor도 포함하지 않은 모델로 모든 관측값에 대해 평균값으로 예측하는 모델이다.2단계:feature 개수별 후보 모델 탐색변수가 \(p\)개있고 그 중 \(k\)개에 대..