[빅데이터 및 지식관리시스템] ER Data Model과 Logical DB Design 공부내용 정리
ER Data Model
ER Data model만으로는 데이터를 조작하거나 검색하는 기능이 없다.
또한 query언어도 없다.
그러나 시각적으로 구조를 표현하기 쉽기 때문에 논리적 데이터 베이스 스키마 설계에 매우 유용하다.
How to design the Database
- Requirement analysis: 사용자 그룹과 비공식적인 논의를 통해 요구사항을 분석한다.
- Conceptual Design: ER 다이어그램을 이용하여 Entity(데이터의 주요 객체), Relationship(관계), Constraints(무결성)을 설계한다.
- Logical Design: PK, FK, Check, Assertion 등을 통해 제약조건을 설계하여 schema로 변환한다.
- Physical Design: Create Table구문으로 실제 테이블을 생성한다.
Entities
- Entity: 현실세계에서 구분 가능한 객체, 하나의 Entity는 여러 개의 속성(attribute)을 가졌다.
- Entity Set: 유사한 Entity들의 집합
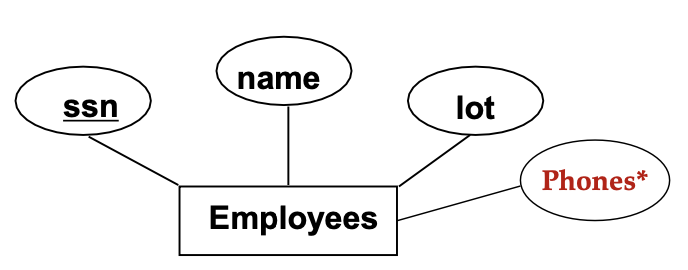
Employees라는 entity에 ssn, name, lot, phones라는 attributes가 있고 ssn은 key이며 각 attribute마다 domain이 있다.
ER 모델에서는 다중 값을 허용하는데 phones*는 한직원이 여러 phone을 가질 수 있음을 보여준다.
그냥 entity나 entity set이나 똑같은 것 같다.
Relationships
- Relationship: 두 개 이상의 Entity 간의 연관 또는 관계이다.
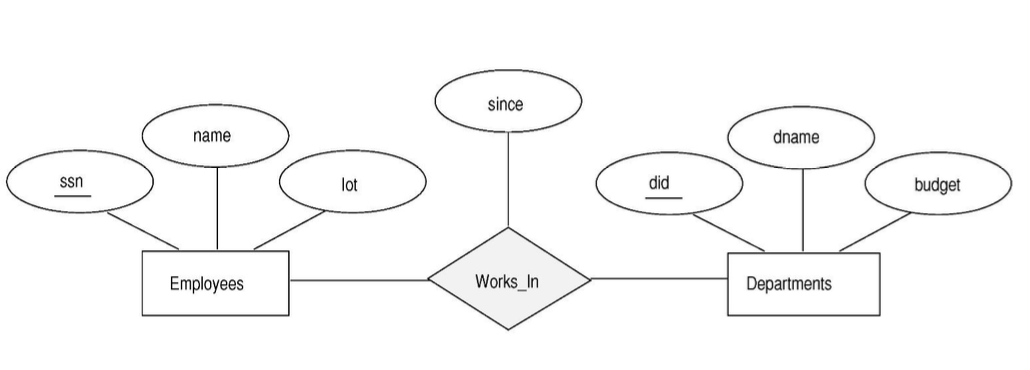
예를 들어 employees라는 entity와 departments라는 entity의 관계를 표현할 수 있다.
Relationship도 attribute를 가질 수 있는데 employees가 departments에서 어떤 시점부터 근무했는지를 since라는 attribute을 통해 나타낼 수 있다.
이를 descriptive attributes라 한다.
- Relationship Set: 유사한 관계들의 집합이다.
n-ary관계가 가능한데 binary는 2개의 entity를 연결한 것이고 ternary는 3개의 entity를 연결한 것이다.
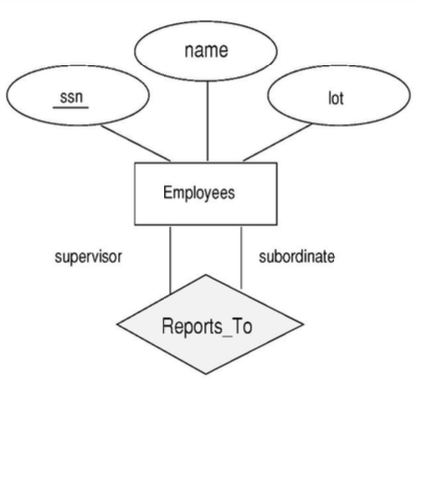
또한 한 entity는 여러 relationship에 참여할 수 있다.
위 예시를 보면 employees entity는 works_in, reports_to relationship 모두 참여할 수 있다.
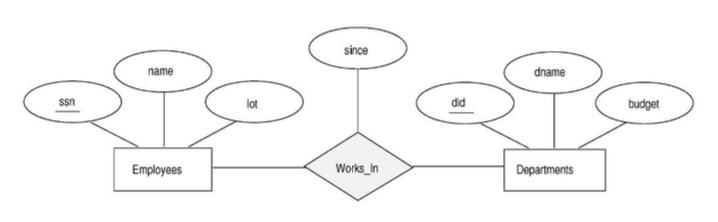
Relationship Set and Its Instance-M:N
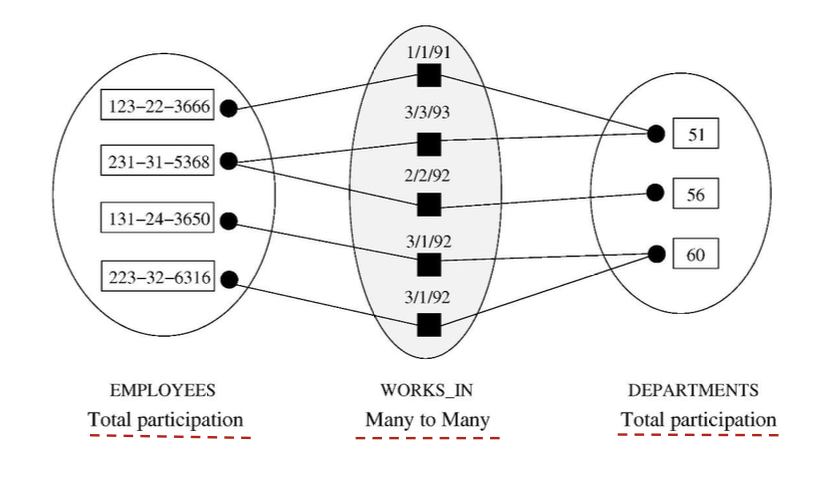
각각 EMPLOYEES의 instance와 DEPARTMENTS의 instance의 관계를 나타낸 것이다.
한 명은 여러 부서에 속할 수 있고 한 부서에 여러 명이 속할 수 있는 관계다.
ER Model은 1:1 관계뿐만 아니라 N:M관계에도 적용된다.
Key Constraints
몇 대 몇 관계를 나타내는 것으로
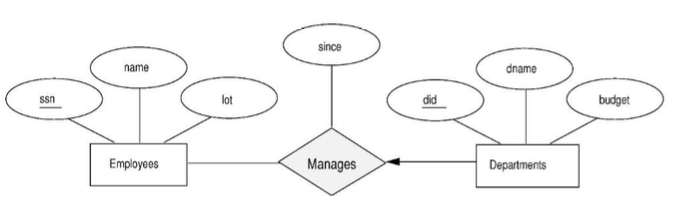
Works_in은 M:N관계이고 Manages는 Departments에 대해 화살표로 constraints가 걸려있다.
Department는 오직 1개의 employee(매니저)만 가질 수 있다.(M:1)
M:1, 1:M이 서로 헷갈릴 수 있는데, M:1로 봤을 때 오른쪽에 있는 entity는 왼쪽에 있는 entity를 하나밖에 못 가지는 것이다.
1:M은 왼쪽의 entity가 하나의 오른쪽 entity를 가질 수 있다.
이제 ER model을 관계형 데이터베이스 schema로 표현하는 방법을 알아보자.
Participation Constraints
관계 참여 종류가 total 또는 partial로 나뉘는데 이 것을 Constraints로 이용할 수 있다.
모든 departments가 반드시 manager와 연결되어 있어야 할까?
먼저 그렇다면 departments entity는 참여가 필수라는 뜻이고 total participation 제약조건이 걸린다.
없어도 된다면 partial participation이다.
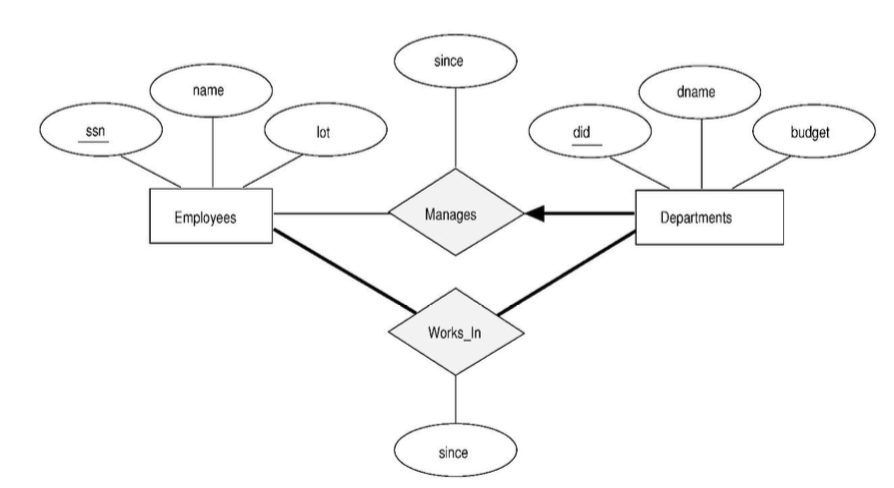
total participation은 다이어그램에서 bold로 표현된 선을 통해 알 수 있다.
total participation으로 managers table을 만들 때, department의 모든 did는 반드시 manages 테이블에 등장해야 한다.
또한 해당 행의 ssd(key) 또한 NULL값이면 안된다.
Entity Sets to Tables
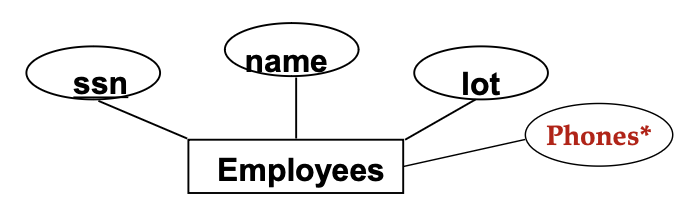

위는 Employees entity을 Table로 구현하는 것이다.
ssn은 key의 역할을 하므로 PRIMARY KEY라 지정할 수 있다.
그럼 다중 값인 Phones*는 어떻게 해야 할까?
RDB에서는 모든 필드는 Atomic Value를 가져야 하기 때문에 복수 값 저장이 불가능하다.
따라서, 따로 테이블을 만들어야 한다.

다음과 같이 따로 설계할 수 있다.
Relationship Sets to Tables


다음과 같은 Relationship set을 Table로 바꿀 때,
각 Entity key의 조합이 관계 테이블의 SuperKey가 된다.
이 둘은 Foreign Key로도 사용된다.
since라는 relationship attribute도 동일하게 설정한다.
Relationship set을 구성하는 table은 ssn, did, since로 구성되고 (ssn, din)의 구성으로 된 primary key와 Foreign key(ssn, did)로 구성된다.
이 경우는 key constraint가 없는 경우(M:N)였고 constraint가 있을 때는(M:1) 어떻게 할까?
두 가지 방법이 있다.
Translating ER Diagrams with Key Constraints
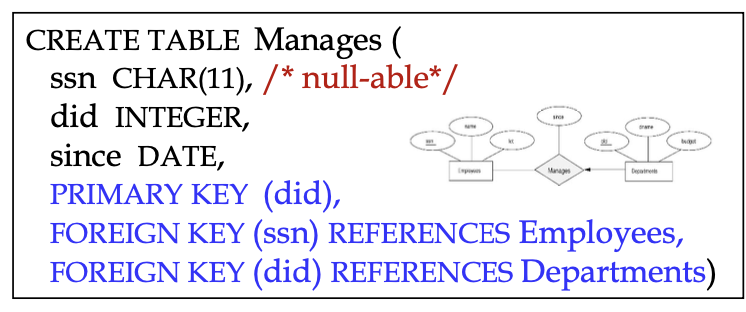

두 방법 모두 '한 부서는 한 매니저만'이라는 Key constraint를 반영하지만, 모든 부서가 반드시 매니저를 가져야 하는(total participation) 것은 보장하지 않는다.
왼쪽 code(manages 테이블로 분리)를 보면 departments의 did가 primary key가 되면서 하나의 부서에 하나의 매니저만 가능하다.
ssn에는 다른 제약을 하지 않아 total participation을 보장하지는 않는다.
오른쪽 code(Dept 테이블에 ssn을 통합) departments와 manages를 하나의 테이블로 결합하였다.
이 경우도 departmetns의 did가 primary key가 되면서 하나의 부서에 하나의 매니저만 가능하다.
그럼 bold로 표시된 total participation을 제약조건으로 걸려면 어떻게 해야 할까?
total participation을 직접적으로 강제 구현은 조금 복잡하다.(나도 잘 모름)
따라서 여기서는 간단한 방법만 설명하면

NOT NULL을 통해 ssn값이 NULL이 되지 않도록 간접적으로 표현할 수 있다.
특히 여기서 ON DELETE CASCADE로 할 경우 직원 삭제 시 해당 부서 매니저도 사라진다.
Translating Class Hierarchy
즉, 3가지 테이블 변환 방법이 있는데
- 각 클래스마다 테이블을 형성하는 것이다.
EMP(ssn, name, lot)
H_EMP(ssn, name, lot, h_wages, h_worked)
C_EMP(ssn, name, lot, contractid)단순하고 각 클래스 별로 정보를 관리할 수 있다. 그러나 데이터 무결성을 지키기 어렵고 중복이 발생한다.
- 상속 테이블 구조
EMP(ssn, name, lot)
H_EMP(ssn, h_wages, h_worked)
C_EMP(ssn, contractid)ssn을 통해 EMP에 공통정보를 보관하는 것이다.
중복이 없어지고 정규화를 하는 작업이다.
그러나 JOIN작업이 필요하며 복잡한 query를 날려야 한다.
- 단일 테이블
EMP(ssn, name, lot, emp_type, h_wages, h_worked, contractid)모든 하위 속성을 포함하고 emp_type으로 구분한다.
query가 편하지만 NULL값이 많고 Redundancy가 발생한다.
편리하지만 이런 Redundancy로 인해 생기는 문제가 많다.
따라서 Redundancy를 제거해야 한다.
The Evils of Redundancy

rating=8인 사람마다 hourly_wages=10이 반복된다.
이럴 경우 3가지 문제가 발생하는데
- Update anomaly: 한 군데만 수정해도 되는데 여러 행을 모두 수정해야 한다.
- Insertion anomaly: 일부 정보가 없으면 추가할 수 없다.
- Deletion anomaly: 한 사람만 지웠는데 그에 해당하는 모든 정보가 제거된다. 지운 사람이 한 명인데 그 사람밖에 없을 때 다시는 그 정보를 접근할 수없게 된다.
Decomposition of a Relation Schema
이런 문제를 막기 위해 Decomposition을 진행한다.
관계형 데이터베이스에서 한 개의 테이블을 둘 이상의 테이블로 나누는 것을 의미한다.
- 각 나눠진 새로운 relation은 기존 relation의 attribute의 부분집합을 가져야 한다.
- 모든 원래 attribute은 새로운 relation 중 하나 이상에 포함되어야 한다.
위의 예시에서 redundancy를 해결하기 위해 rating과 hourly_wages를 attribute으로 하는 relation으로 decompose 해야 한다.
하지만 decompose 할 때도 문제가 있는데
아무래도 분리해 놨다가 query를 날리면 다시 합치는 join 연산을 하기 때문에 performance가 저하될 수 있다.
또한 information loss, dependency loss가 생길 수 있다.
따라서, 신중하게 분해해야 한다.(좋은 조건일 때만)
신중하게 분해하기 위해서 Functional dependency를 이용하는데
Functional Dependencies
속성 \(X\)의 값이 주어졌을 때, 속성\(Y\)의 값이 반드시 하나로 결정되는 관계를 의미한다.
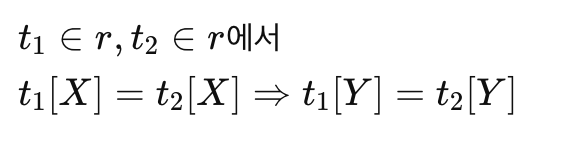
데이터베이스 무결성 제약 조건의 일종이다.