[빅데이터 및 지식관리시스템] SQL의 기본연산에 대해 알아보기(Join에 대해 모든 공부..)
SQL과 같은 실제 질의 언어가 어떤 수학적 기초 위에 구축되어 있을까??
SQL언어는 Relational Algebra와 Relational Calculus에 근간하여 만들어졌다.
- Relational Algebra
실제 SQL 질의 실행 계획을 표현하는 것으로 operational 하고 procedural 한 성격을 띤다.
일련의 연산을 사용해 데이터를 조작한다.
- Relational Calculus
사용자가 query에 대해 how to coplete it을 보는 것보다 what they want를 보는 것이다.
따라서, non-operational 하고 declarative 하다.
RA와 RC는 전환이 가능하며 표현력이 비슷하다.
Relational Algebra
Algebra는 mathematical system으로 Operands, Operators, Axioms로 구성돼 있다.
Relational Alegebra도 동일한데
- Operands: relations이나 relations을 나타내는 variables를 말한다.
- Operators: relation에서 일어나는 모든 연산 같은 것을 말하는 것이고 가장 기본적인 연산으로 덧셈이 있다.
- Selection: relation에서 row를 고르는 것
- Projection: relation에서 column을 고르는 것
- Cross-product: 두 relation을 합치는 것(Cartesian prod)
- Set-difference: \(R_1\)-\(R_2\)으로 \(R_1\) 에는 있고 \(R_2\) 에는 없는 것
- Union: 합치는 것
- Closedness: relation 대수의 연산 결과가 다시 relation으로 나온다는 성질입니다. 이로 인해 어떤 연산 결과도 다른 연산의 입력으로 사용될 수 있다.
- Three Axioms: relation algebra에서 주로 다루는 연산은 Cartesian Product다.
- Commutativeness(교환법칙): 연산의 순서를 바꿔도 생성되는 값은 동일하다. 단, 물리적 처리 비용이나 접근 방식이 달라질 수 있다.
- Associativeness(결합법칙): Cartesian Product를 여러 번 연달아할 때, 어떤 관계끼리 먼저 곱하든 결과적으로 같은 집합을 얻게 된다는 것이다.
- Distributiveness(분배법칙): Catesian Product과 union 연산사이에 성립한다.
Projection

projection list에 없는 column은 지우는 것이다.
projection operator는 중복을 무조건 지워야 한다. set기반 relation이기 때문이다.
그러나 real system에서는 중복된 것을 지워줄 필요 없아.(그게 실사용에서는 더 맞으니깐)

다음과 같이 age에 대해 projection을 할 경우, 35.0 instance가 중복됐기 때문에 projection 후에는 어떻게 될지에 관한 문제다.
앞서 말했듯이 set기반 relation이기 때문에 이론적으로는 지워야 하지만 real system에서는 안 지운다.
select job from emp;
다음과 같이 job에 대해 projection을 실제로 해보면 중복된 값이 나온다.
그러나 이런식으로 distinct를 붙여주면
select distinct job from emp;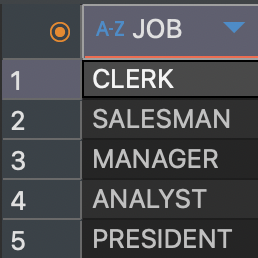
중복을 제거한다.
Selection
row에서 selection condition에 부합하는 것을 선택하는 것이다.
이 또한 set을 기반으로 하기 때문에 중복을 둘 수 없다.
따라서 output schema가 input schema와 동일한 Selection은 중복을 둘 수 없다.
참고로 where 조건에 null값을 거르고 싶다면
select * from emp where comm is null(is not null)Union, Intersection, Set-Difference
이 operator는 두 개의 입력 relation을 받는 binary 연산이다.
따라서 두 relation이 Union-compatible 해야 한다.
동일한 field 수를 가지고 대응되는 각 field의 domain type도 같아야 한다.
연산을 하고 난 뒤의 result schema도 입력들과 동일 schema를 가져야 한다.
- Union 연산(중복 제거)
select * from r union select * from s- Union 연산(중복을 제거하지 않는 경우)
select * from r union all select * from s;- intersect 연산
select * from r intersect select * from s;- minus 연산
select * from r minus select * from s;Cross Product
Cross Product는 Cartesian Product라고도 하는데, R1 X S1에 대하여 R1의 모든 튜플과 S1의 모든 튜플을 모든 가능한 쌍으로 만들어 새로운 관계를 생성하는 이항 연산이다.
R1이 m개의 row가 있고 S1이 n개의 column이 있다고 할때, result table은 m*n개의 row가 생성된다.
특히, 테이블을 합칠 경우 같은 이름의 column이 있다면 중복된 column명을 renaming operator가 이름을 바꾼다.
(oracle에서는 애매하니깐 error를 내뱉는다.)
select deptno from emp, dept;이 경우 error가 발생한다.
그러나 다음과 같이 명시적으로 어떤 table에서 가져올지 정해주면 error가 해결된다.
select emp.deptno from emp, dept;또한 tuple variable을 다음과 같이 정하면 좀더 편하다.
select e.deptno from emp e, dept d;emp를 e로 dept를 d로 정하는 것
SQL과 Relation Algebra
relation algebra의 이론이 sql로 어떻게 구현되는지 보면

Cartesian product를 하여 새로운 table을 만들고 selction을 이용하여 row에 조건을 건다.
마지막으로 projection을 하여 원하는 column만 본다.
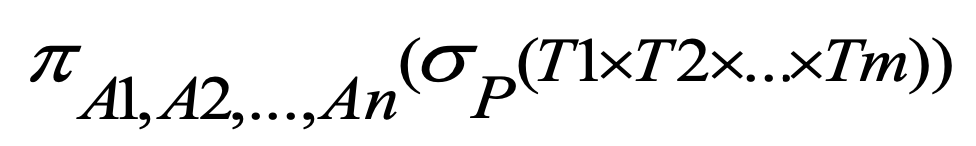
relation algebra의 operational, procedure한 특징을 볼 수 있다.
join
table과 table을 엮어서 생각할 때(특정 조건에 따라 결합), 많이 쓰는 operator로 잘 알고 있어야한다.
종류는 3가지가 있고 condition join이 좀 더 실용적인 면에서 의미가 있다.
근데 natural join만 써도 모든 것을 커버할 수 있는 것 같다.
- Condition Join: 튜플을 선택하는 조건을 다음과 같이 작성한다.(\(R.sid=S.sid, R.age< S.age\))

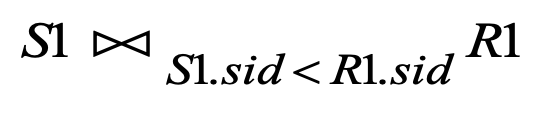
- Equi Join: condition join의 특수한 형태로, join 조건이 "="만 포함될 때를 말한다.
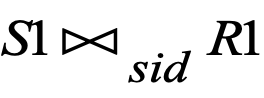
select ename from emp e, dept d where e.dptno=d.deptno and loc=”NEWYORK” and job=”Manager”- Natural Join: 두 테이블이 공통으로 가진 모든 row이름에 대해 자동으로 =조건을 적용하는 것이다.
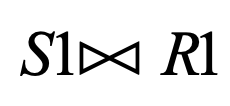
select enmae from emp e natural join dept d where loc=”NEWYORK” and job=”MANAGER”여기서 join에 대한 정보를 안알려주면 정확한 join이 안된다. 다음의 경우가 그 예시이다.
select ename from emp e, dept d where loc=”NEWYORK” and job=”Manager”꼭 join에 대한 정보를 넣어줘야한다!